Using Neural Networks
Open Domain Targeted SA investigates the classification of sentiment polarities towards certain target entity mentions.
Targets aren't given to you (as opposed to Targeted Sentiment Analysis)
Targets are not limited to Named Entities. Can be any Noun Phrase
Examples of targets
singing in the bath
the best defense against Trump
Windows 7
American imperialism
Uses in typical NLP tasks such as Information Extraction, Summarization, Question-Answering
Source help in a crisis
Understand public opinion

NLP can help

هذه من منجزات (الثورة) و الأتي أعظم،، هنيئاً لكم ثورتكم،،و بعد التجارب الليبية و العراقية و المصرية و ما شاهدناه من دمار و قتل و إستعمار،، نحن في سوريا لا نريد ثورة الفوضة الخلاقة الأميركية. نريد سوريا الأمن و الأمان و العروبة الصادقة
What're the targets of positive and negative sentiment here?
This is one of the achievements of the revolution and more to come, Congratulations to you and your revolution, after Libyan experiences and Iraqi and Egyptian and what we saw destruction and killing and colonization, We in Syria do not want the American creative chaotic revolution. We want Syria's security and safety of Arabism and sincere
Farrah 2015
1200 online comments posted to Aljazeera newspaper articles
4886 targets: 38.2% positive, 50.5% negative, and 11.3% ambiguous
~ 100,000 words and a vocabulary ~ 10,000
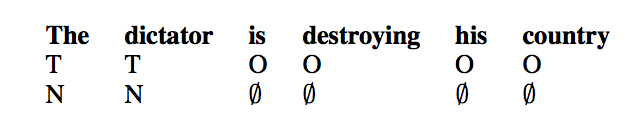
Morphology
ATB splitting off all the clitics and particles, but keeps the definite article Al+ attached
D3 splitting off all the clitics, particles, and prepositions (Al+)
Original:"bEwn AlHkwmh"
Translation(lemma): with(help)from the(Government)
ATB Tokenized: b+, Eawon_1, Hukuwmap_1
D3 Tokenized:b+, Eawon_1, Al+, Hukuwmap_1
Pipelined two CRF models
Tested with different morphological schemes using MADAMIRA
Introduced rich linguistic features
Added word2vec cluster IDs for distributed representation
Farrah 2016
We continued this approach of breaking the task down into two components
Allows for modularity
Can better address sparsity issues on a small dataset
Easier to "debug"
Two tasks
Target Extraction (as a sequence labeling task)
Target Dependent Sentiment Classification (as a binary classification task)
Can we beat the CRF results?
Can we greatly reduce the feature engineering step?
Karpathy 2015
We predict targets using a Many to Many Architecture
Kiperwasser 2016, Goldberg 2015, Cho 2015
Word Vectors
Used Arabic Wikidump to pretrain word vectors
Used fasttext library to train skipgram with negative sampling with dimension 50
Trained word vectors on a variety of morphological schemes (lemma, ATB, D3)
Initial architecture we want to build

Keras
Python Deep Learning library
Easy to experiment with different architectures
Tensorflow or Theano Backend
Word features
lexical_model = Sequential()
lexical_model.add(Embedding(
server.vocab_size,
embedding_size,
input_shape=MAX_SEQ_LEN,
weights=embedding_weights,
trainable=args.fine_tune))
POS features
pos_model = Sequential()
pos_model.add(Embedding(
num_pos_tags,
input_shape=MAX_SEQ_LEN,
init="glorot_normal",
trainable=args.fine_tune))
Merge
model_list = [lexical_model, pos_model]
merged =Merge(model_list, mode='concat')
model = Sequential()
model.add(merged)
model.add(
LSTM(RNN_SIZE,
return_sequences=True,
dropout_W=.2))
model.add(Dropout(0.2))
Prediction and Compilation
model.add(TimeDistributed(Dense(server.num_classes, activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
sample_weight_mode='temporal',
metrics=['accuracy'])
No knowledge of Arabic
But I do know English :)
Figure out simple way to understand errors on validation data
Key insight
Process input in reverse
Final Architecture

Retrofitting to Sentiment Lexicons
Inspired by Retrofitting Word Vectors to Semantic Lexicons by Faruqui et al
Set of modified word vectors was too small for any real benefit. Almost no overlap with the validation set.
Tried collapsed model, training the LSTM end to end
Positive(T), Negative(T), Neutral(O)
Target Prediction was okay, Sentiment Accuracy was subpar (65 % Sentiment accuracy)
Data sparsity issues
model.load_weights(args.transfer_model, by_name=True)
Ended up predicting neutral most of the time
Simplified the problem
Given the target, predictive positive or negative
Use local context as feature input
No longer a sequence labeling task, just a binary classification task.
A comment with 3 predicted targets would create three examples.
"Increased" training data
Sparsified feature space
Vowpal Wabbit
LSTM (many to one)
CNN
Hyperparameter tuning
context window of 6 was optimal on validation set
Neural models tend to favor recall over precision
Lemmas capture majority of the information
ATB and D3 increase recall further at the cost of precision
Adding dropout (.2) to the lexical input with no dropout for the POS input worked best
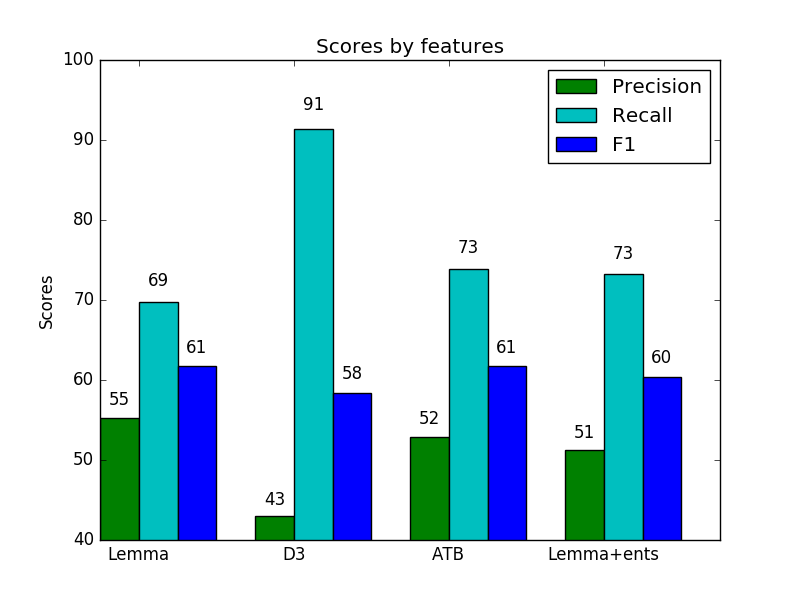
Models with high recall got penalized in final F score due to lower precision
Simple linear model with bag of ngram features maintained good accuracy (Over 70%)
Key takeaways
With less data, break the task down
Take full advantage of latent representions with less sparsity
Do error analysis
Word vectors + RNNs = Powerful building blocks to play around with in any language
Future work
Try to increase dataset by an order of magnitude (distantly supervised)
Improve error analysis tools
Introduce attention model